Genetics 1F
Coding for Amino Acids
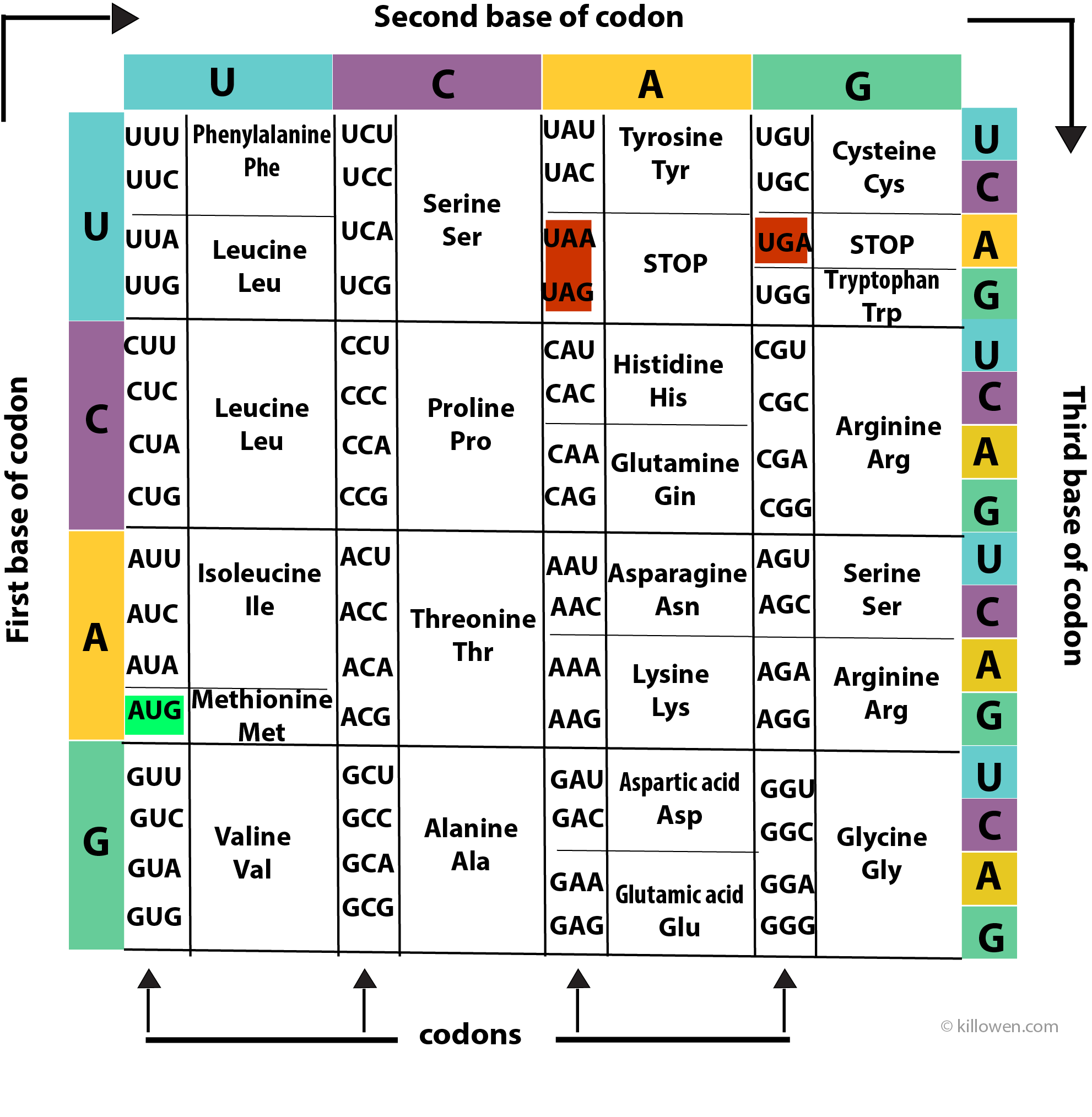
A protein is made up of a series of amino acids. A protein-coding gene determines the order in which the amino acids are assembled onto the protein chain. Each amino acid is determined by a triplet of nucleotides or codon present along the RNA molecule. The 4 bases (A, C, G, and U) can be arranged in 64 different combinations of 3 bases (4 x 4 x 4 = 64). Each combination or codon then produces an amino acid. However, because there are only 20 common amino acids this means that each amino acid can be produced by more than one codon i.e. the genetic code is degenerate except for two amino acids methionine (AUG) and tryptophan (UGG).
The coding information for the 20 amino acids is summarised in above diagram. The coding for the first, second, and third bases is read clockwise around the grid.
There are also codons which determine the start and the termination of the coding sequence. Three codons (UAA, UAG, and UGA) act as STOP codons at the end of a protein-coding gene. AUG acts as a START codon when it appears at the front end of the gene, but also codes for methionine when it is found elsewhere on the gene.
The coding information for the 20 amino acids is summarised in above diagram. The coding for the first, second, and third bases is read clockwise around the grid.
There are also codons which determine the start and the termination of the coding sequence. Three codons (UAA, UAG, and UGA) act as STOP codons at the end of a protein-coding gene. AUG acts as a START codon when it appears at the front end of the gene, but also codes for methionine when it is found elsewhere on the gene.
Amino acids
Amino acids have been met with throughout this text. They are the fundamental building blocks of proteins many of which in turn act as enzymes. So to look at the structure of an amino acid in more detail.
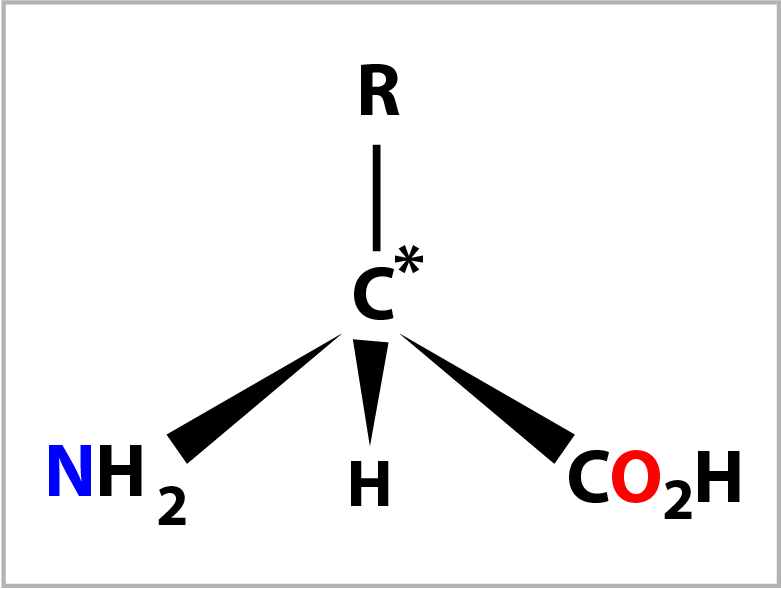
An amino acid is composed of a central carbon atom (C*) to which are bonded 4 groups.
When the 4 groups are different this carbon atom is called a chiral centre. The 4 groups are: an amino group (-NH2), a carboxylic acid group (-CO2H), a hydrogen atom (-H) and a forth group (-R) which defines the amino acid. There are 20 variants for the forth group and hence 20 naturally occurring amino acids. The 4 groups are arranged tetrahedrally (bond angle= 109°) around the central carbon atom with the amino group conventionally placed on the left and the carboxylic acid group on the right. The diagram on the right shows the bonds drawn in perspective where the C* and -R grouping are in the plane of the screen.
Amino acids have been met with throughout this text. They are the fundamental building blocks of proteins many of which in turn act as enzymes. So to look at the structure of an amino acid in more detail.
An amino acid is composed of a central carbon atom (C*) to which are bonded 4 groups.
When the 4 groups are different this carbon atom is called a chiral centre. The 4 groups are: an amino group (-NH2), a carboxylic acid group (-CO2H), a hydrogen atom (-H) and a forth group (-R) which defines the amino acid. There are 20 variants for the forth group and hence 20 naturally occurring amino acids. The 4 groups are arranged tetrahedrally (bond angle= 109°) around the central carbon atom with the amino group conventionally placed on the left and the carboxylic acid group on the right. The diagram on the right shows the bonds drawn in perspective where the C* and -R grouping are in the plane of the screen.
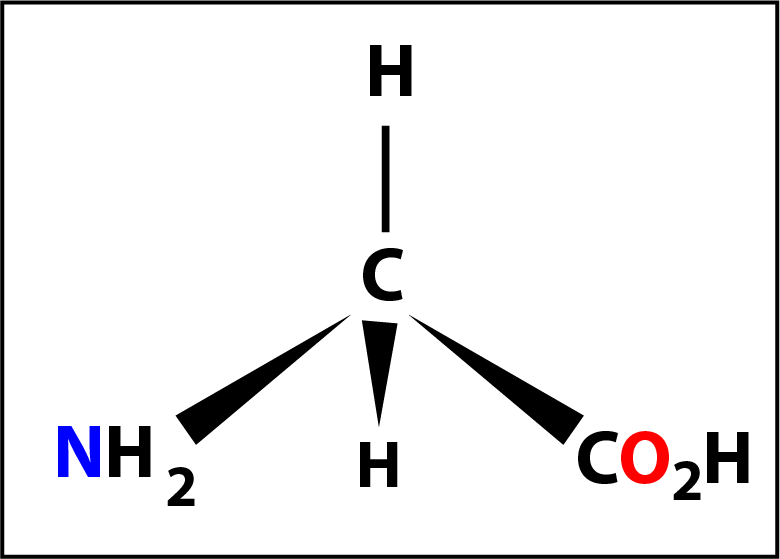
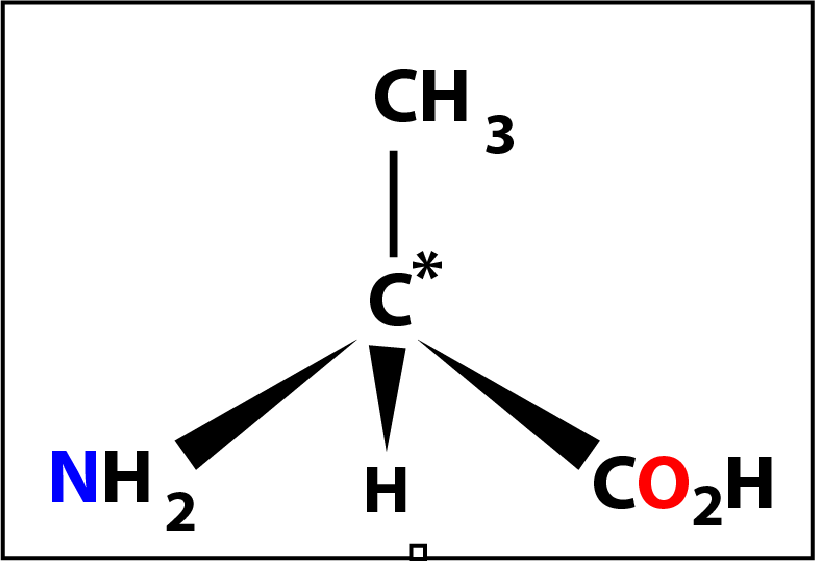
Of the 20 naturally occurring amino acids glycine (shown on the left) might be considered to be the first of the series. Here the -R group is a hydrogen atom -H and the molecule does not have a chiral centre (because the 4 groups are not different).
The next member might be considered to be alanine where the -R group is a methly group -CH3 with the central carbon again a chiral centre. In this case the molecule has a special property in that it can exist in 2 forms (called optical isomers) which are mirror images of one another.
The next member might be considered to be alanine where the -R group is a methly group -CH3 with the central carbon again a chiral centre. In this case the molecule has a special property in that it can exist in 2 forms (called optical isomers) which are mirror images of one another.
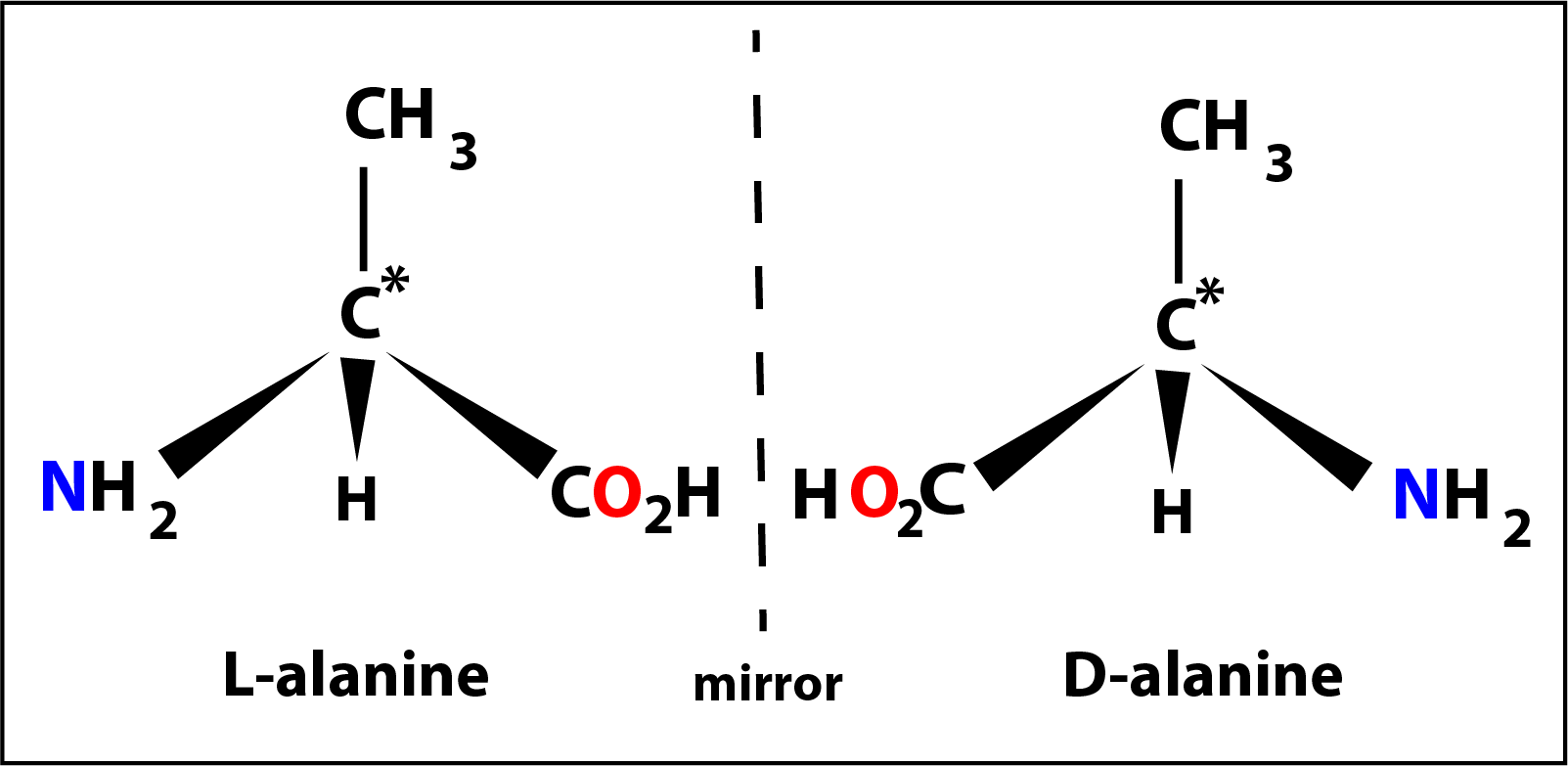
The 2 isomers of alanine are shown in the diagram on the left designated as L- (laevo) and D- (dextro).
All 19 amino acids (apart from glycine) are able to exist as similar L- and D- isomers but in nature only the L-isomer is found.
All 19 amino acids (apart from glycine) are able to exist as similar L- and D- isomers but in nature only the L-isomer is found.
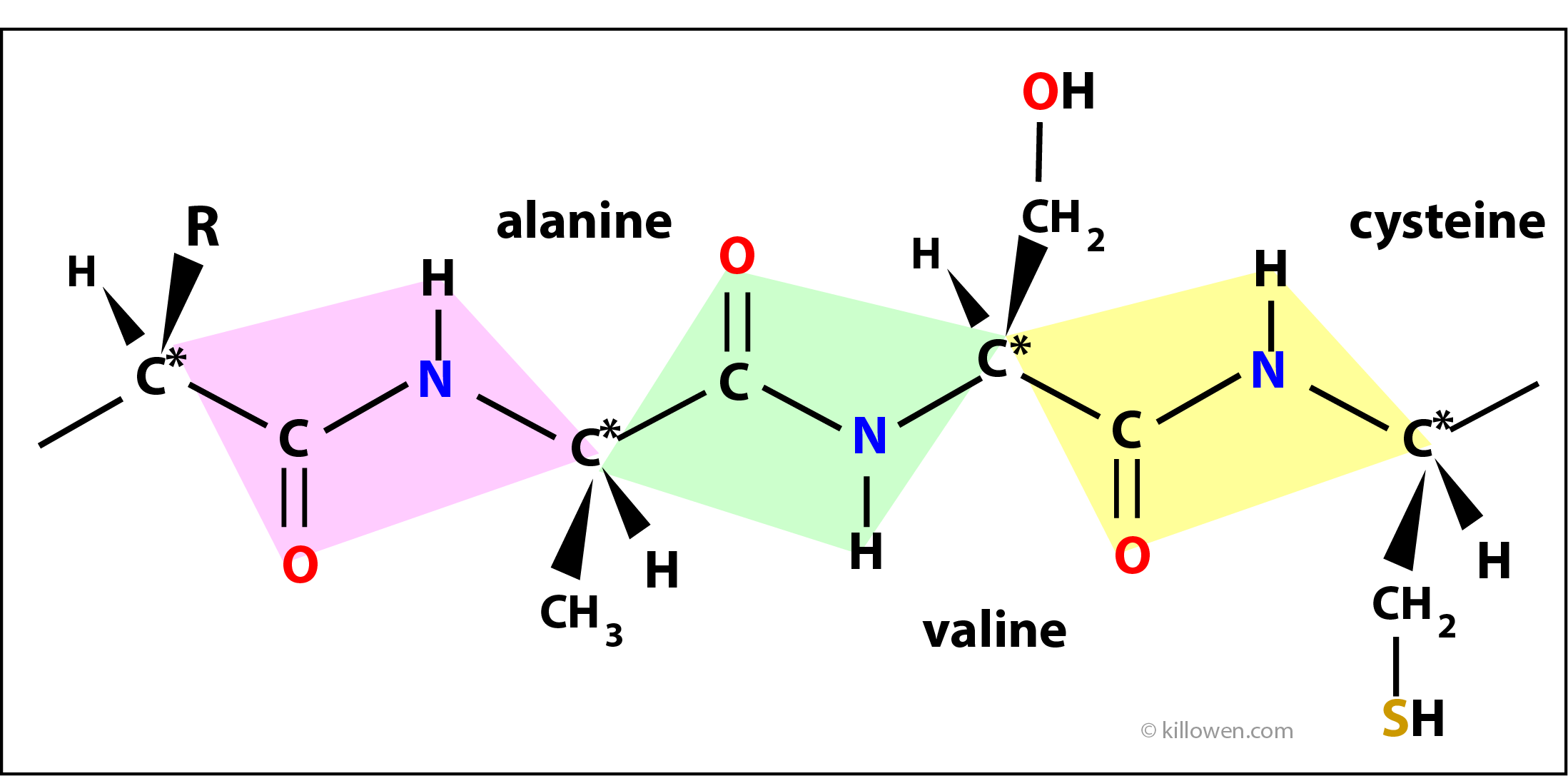
Polypeptides
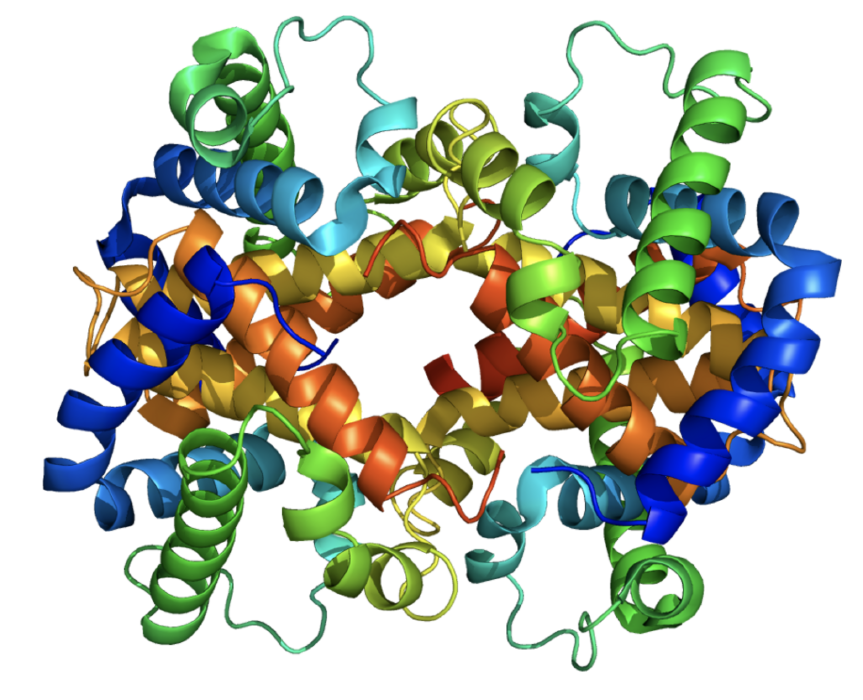
Amino acids join together in a linear chain to form proteins. Two amino acids join together with the elimination of a molecule of water forming a special linkage called a peptide bond. In the diagram 3 amino acids are shown linked together through the peptide linkage. The atoms in each coloured box form the peptide link and lie in the same plane. The planes gradually twist as the polypeptide chain grows. As well as this rotation there is also hydrogen bonding between groups within the protein structure which hold the molecule in a unique three dimensional form. It is this folding that allows the protein to carry out its biological function.
For example the complexity of the folding is shown in a model of a haemoglobin molecule.
Amino acids join together in a linear chain to form proteins. Two amino acids join together with the elimination of a molecule of water forming a special linkage called a peptide bond. In the diagram 3 amino acids are shown linked together through the peptide linkage. The atoms in each coloured box form the peptide link and lie in the same plane. The planes gradually twist as the polypeptide chain grows. As well as this rotation there is also hydrogen bonding between groups within the protein structure which hold the molecule in a unique three dimensional form. It is this folding that allows the protein to carry out its biological function.
For example the complexity of the folding is shown in a model of a haemoglobin molecule.