Genetics 1E
DNA expression - Protein synthesis
In the text below DNA expression is looked at; that is how a gene codes for a protein. A protein is made up of a series of amino acids. A protein-coding gene determines the order in which the amino acids are assembled onto the protein chain. There are two steps in this process firstly gene transcription whereby the gene is transcribed to messenger RNA (mRNA), and secondly translation when the mRNA is translated to a protein. Haemoglobin is taken as an example in the diagram; shown as a tertiary structure.
In the text below DNA expression is looked at; that is how a gene codes for a protein. A protein is made up of a series of amino acids. A protein-coding gene determines the order in which the amino acids are assembled onto the protein chain. There are two steps in this process firstly gene transcription whereby the gene is transcribed to messenger RNA (mRNA), and secondly translation when the mRNA is translated to a protein. Haemoglobin is taken as an example in the diagram; shown as a tertiary structure.
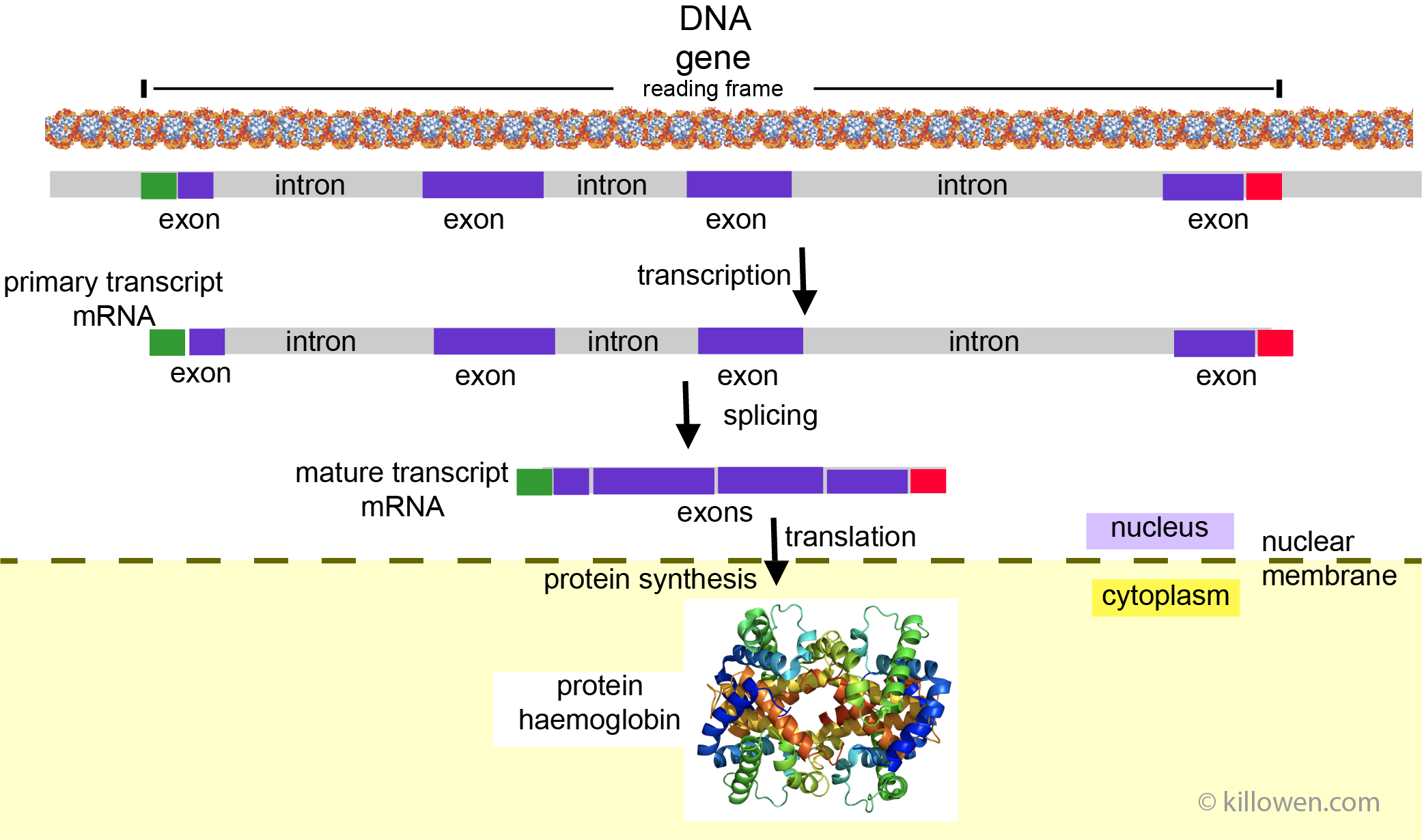
In the above diagram the gene is shown as part of the DNA chain in the cell nucleus. The gene is shown to have a number of sections:  is the start codon,
is the start codon,  is the end codon. In between the gene has coding regions
is the end codon. In between the gene has coding regions  - exons and non-coding regions
- exons and non-coding regions  - introns. In the first part of the process the gene is copied in full to produce a primary transcript; this includes the exons and introns. Secondly through a process called splicing a mature transcript of mRNA is formed where the introns are removed. Spicing has the advantage in that more than one protein can be produced from the one gene according to how the exons are chosen.<br><br>
- introns. In the first part of the process the gene is copied in full to produce a primary transcript; this includes the exons and introns. Secondly through a process called splicing a mature transcript of mRNA is formed where the introns are removed. Spicing has the advantage in that more than one protein can be produced from the one gene according to how the exons are chosen.<br><br>
Transcription
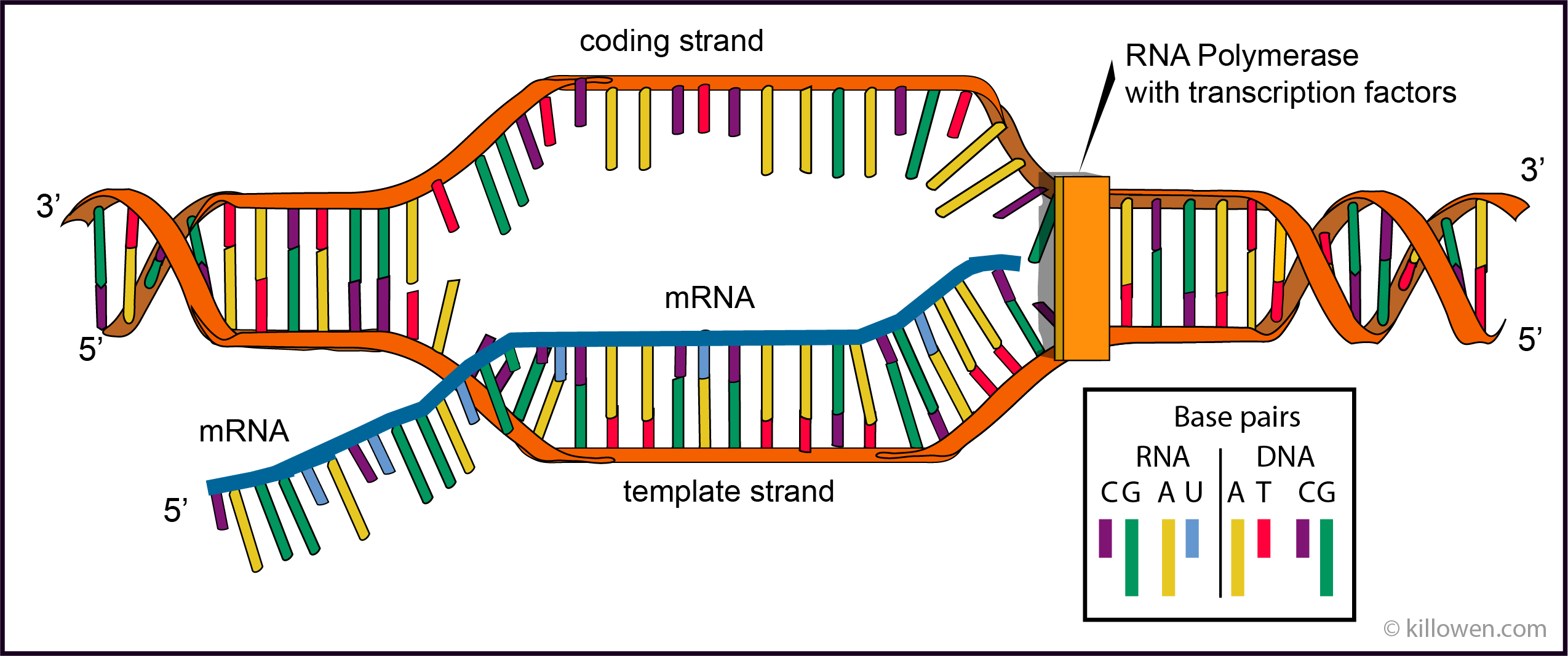
The diagram below represents a simple view of the transcription process. The two strands of the DNA molecule are shown called the template strand and the coding strand.
The enzyme RNA polymerase initiates the synthesis of the mRNA with the assistance of accessory proteins called transcription factors. The latter bind to specific DNA sequences in order to recruit RNA polymerase to the transcription site and the transcription factors also unwind the DNA strand. This then allows RNA polymerase to read the template strand from the 3’ to 5’ end; in the diagram from left to right and synthesises the new mRNA molecule in the 5’ to 3’ direction. This is just like DNA in DNA replication. Complementary base pairing determines the order of the bases along the newly forming mRNA. This coding of the bases on mRNA is identical to that on the coding strand of the DNA molecule except that uracil (U) takes the place of thymine (T). RNA polymerase moves along the DNA until it reaches a terminator sequence. At this point the RNA polymerase releases the mRNA and is detached from the DNA.
The RNA molecule first produced by the polymerase is known as the primary transcript which undergoes further modification before translation takes place. Part of this modification is the splicing out of the introns which eliminates the non-coding region of the gene. What is left is known as the mature transcription containing the coding region of the gene - the exons.
Transcription of course takes place in the cell nucleus but before the next stage can take place the mRNA must pass from the nucleus through the nuclear membrane into the cytoplasm. Once in the cytoplasm ribosomes and transfer RNA work along side one another to translate the mRNA into a protein.
Transcription
The diagram below represents a simple view of the transcription process. The two strands of the DNA molecule are shown called the template strand and the coding strand.
The enzyme RNA polymerase initiates the synthesis of the mRNA with the assistance of accessory proteins called transcription factors. The latter bind to specific DNA sequences in order to recruit RNA polymerase to the transcription site and the transcription factors also unwind the DNA strand. This then allows RNA polymerase to read the template strand from the 3’ to 5’ end; in the diagram from left to right and synthesises the new mRNA molecule in the 5’ to 3’ direction. This is just like DNA in DNA replication. Complementary base pairing determines the order of the bases along the newly forming mRNA. This coding of the bases on mRNA is identical to that on the coding strand of the DNA molecule except that uracil (U) takes the place of thymine (T). RNA polymerase moves along the DNA until it reaches a terminator sequence. At this point the RNA polymerase releases the mRNA and is detached from the DNA.
The RNA molecule first produced by the polymerase is known as the primary transcript which undergoes further modification before translation takes place. Part of this modification is the splicing out of the introns which eliminates the non-coding region of the gene. What is left is known as the mature transcription containing the coding region of the gene - the exons.
Transcription of course takes place in the cell nucleus but before the next stage can take place the mRNA must pass from the nucleus through the nuclear membrane into the cytoplasm. Once in the cytoplasm ribosomes and transfer RNA work along side one another to translate the mRNA into a protein.
 Adapted from an image by LadyofHats
Adapted from an image by LadyofHats Translation
This is the second step in the gene expression in which the information on the newly synthesised mRNA is used to direct the synthesis of a polypeptide. The order of the bases on the newly formed mRNA is shown in more detail in the diagram below. The mRNA has been synthesised from left to right in the 5’ to 3’ direction.
The genetic code consists of a triplet of adjacent bases which specify which amino acid will be the next along the polypeptide chain. The triplet of bases is called a codon. These are illustrated in the diagram below.
This is the second step in the gene expression in which the information on the newly synthesised mRNA is used to direct the synthesis of a polypeptide. The order of the bases on the newly formed mRNA is shown in more detail in the diagram below. The mRNA has been synthesised from left to right in the 5’ to 3’ direction.
The genetic code consists of a triplet of adjacent bases which specify which amino acid will be the next along the polypeptide chain. The triplet of bases is called a codon. These are illustrated in the diagram below.
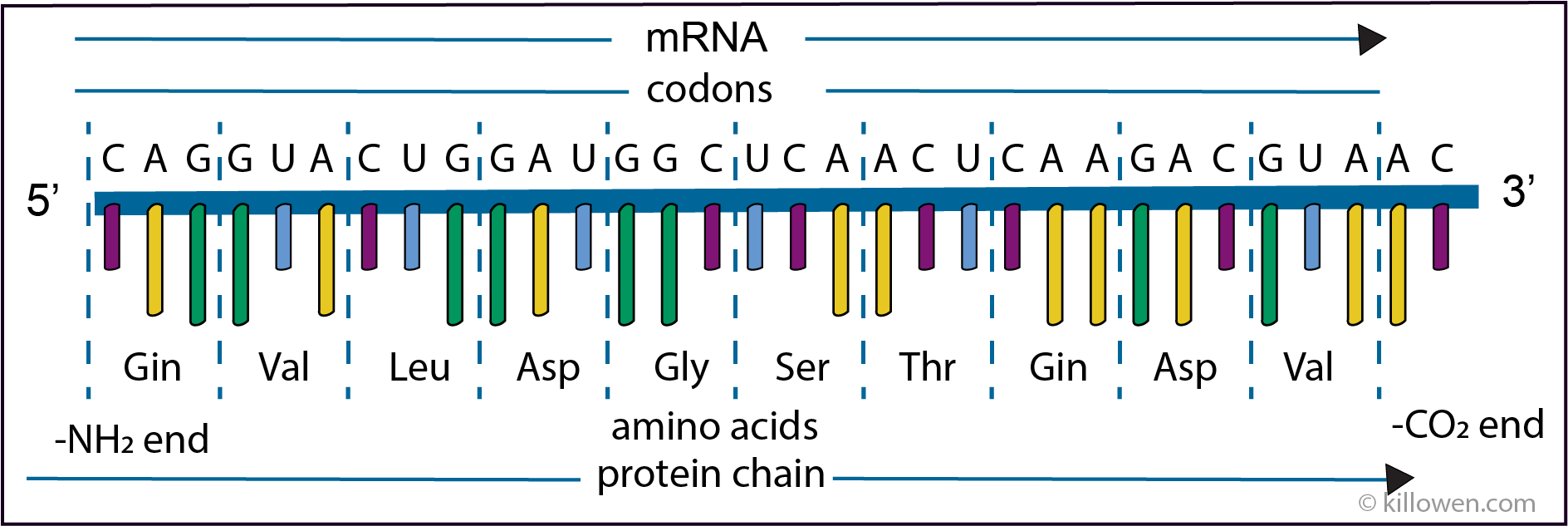
The 4 bases (A, C, G, and U) can be arranged in 64 different combinations of 3 bases (4 x 4 x 4 = 64). Each combination or codon then produces an amino acid. However, because there are only 20 common amino acids this means that each amino acid can be produced by more than one codon i.e. the genetic code is degenerate except for two amino acids methionine (AUG) and tryptophan (UGG).
In the above example the first codon is CAG this codes for glutamine - gin; and so on.
The protein so produced has the amino group -NH2 at the start of the chain and the carboxly group -CO2H at its end.
The diagram on the next page summarises all possible codons and their respective amino acids.
In the above example the first codon is CAG this codes for glutamine - gin; and so on.
The protein so produced has the amino group -NH2 at the start of the chain and the carboxly group -CO2H at its end.
The diagram on the next page summarises all possible codons and their respective amino acids.