Genetics 1B
The diagram attempts to simplify the relationship between the cell nucleus, the chromosome, and the DNA in an animal cell (eukaryote).
The chromosome is a coiled DNA molecule within the cell's nucleus that carries the bees genetic code. Most of the time the chromosome's structure is loose and indistinguishable. Only in the stage of cell division immediately before the cell divides (the metaphase) does the chromosome draw itself into a compact, rod-like structure which can be seen under a microscope after the application of a special dye to the cell which the chromosomes absorb. It is this ability to absorb a coloured dye that gives the chromosome its name, which means "coloured body".
The honey bee (worker or queen) has 16 pairs of chromosomes,
DNA - is the abbreviation for deoxyribonucleic acid. DNA has a characteristic double-helix structure that resembles a gently twisting ladder. The DNA helix does a complete turn for every 10 base pairs. The supporting rails of this structure are deoxyribose, a sugar, attached to a phosphate group. The rungs of the ladder are pairs of nitrogen bases: adenine (A), thymine (T), guanine (G), and cytosine (C).
Complementary Base Pairing: adenine always pairs with thymine; guanine always pairs with cytosine through hydrogen bonding.
More information on the chemical structures of the base pairs can be seen below
A gene is a segment of the DNA (on a specific site on a chromosome - the locus) that is responsible for the physical and inheritable characteristics or phenotype of the bee. It also specifies the structure of a protein, and an RNA molecule.
The chromosome is a coiled DNA molecule within the cell's nucleus that carries the bees genetic code. Most of the time the chromosome's structure is loose and indistinguishable. Only in the stage of cell division immediately before the cell divides (the metaphase) does the chromosome draw itself into a compact, rod-like structure which can be seen under a microscope after the application of a special dye to the cell which the chromosomes absorb. It is this ability to absorb a coloured dye that gives the chromosome its name, which means "coloured body".
The honey bee (worker or queen) has 16 pairs of chromosomes,
DNA - is the abbreviation for deoxyribonucleic acid. DNA has a characteristic double-helix structure that resembles a gently twisting ladder. The DNA helix does a complete turn for every 10 base pairs. The supporting rails of this structure are deoxyribose, a sugar, attached to a phosphate group. The rungs of the ladder are pairs of nitrogen bases: adenine (A), thymine (T), guanine (G), and cytosine (C).
Complementary Base Pairing: adenine always pairs with thymine; guanine always pairs with cytosine through hydrogen bonding.
More information on the chemical structures of the base pairs can be seen below
A gene is a segment of the DNA (on a specific site on a chromosome - the locus) that is responsible for the physical and inheritable characteristics or phenotype of the bee. It also specifies the structure of a protein, and an RNA molecule.
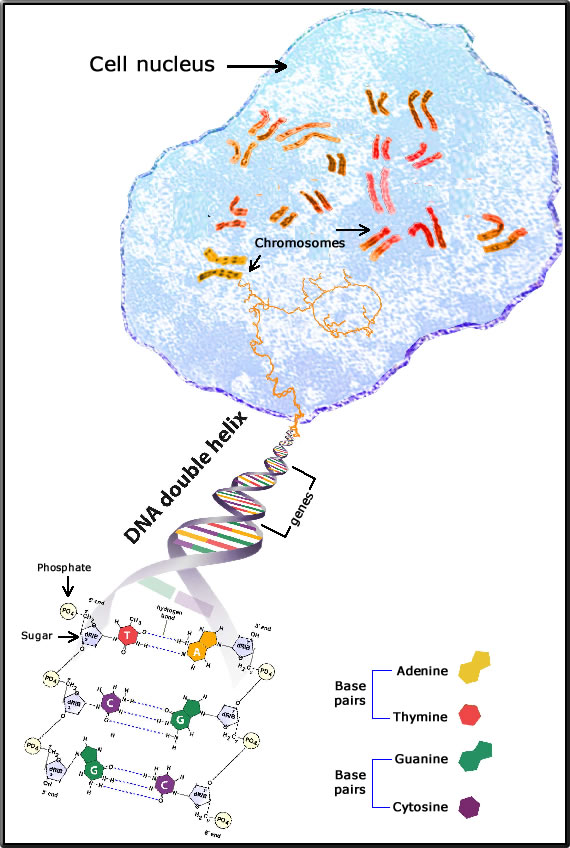
image adapted from genome.gov
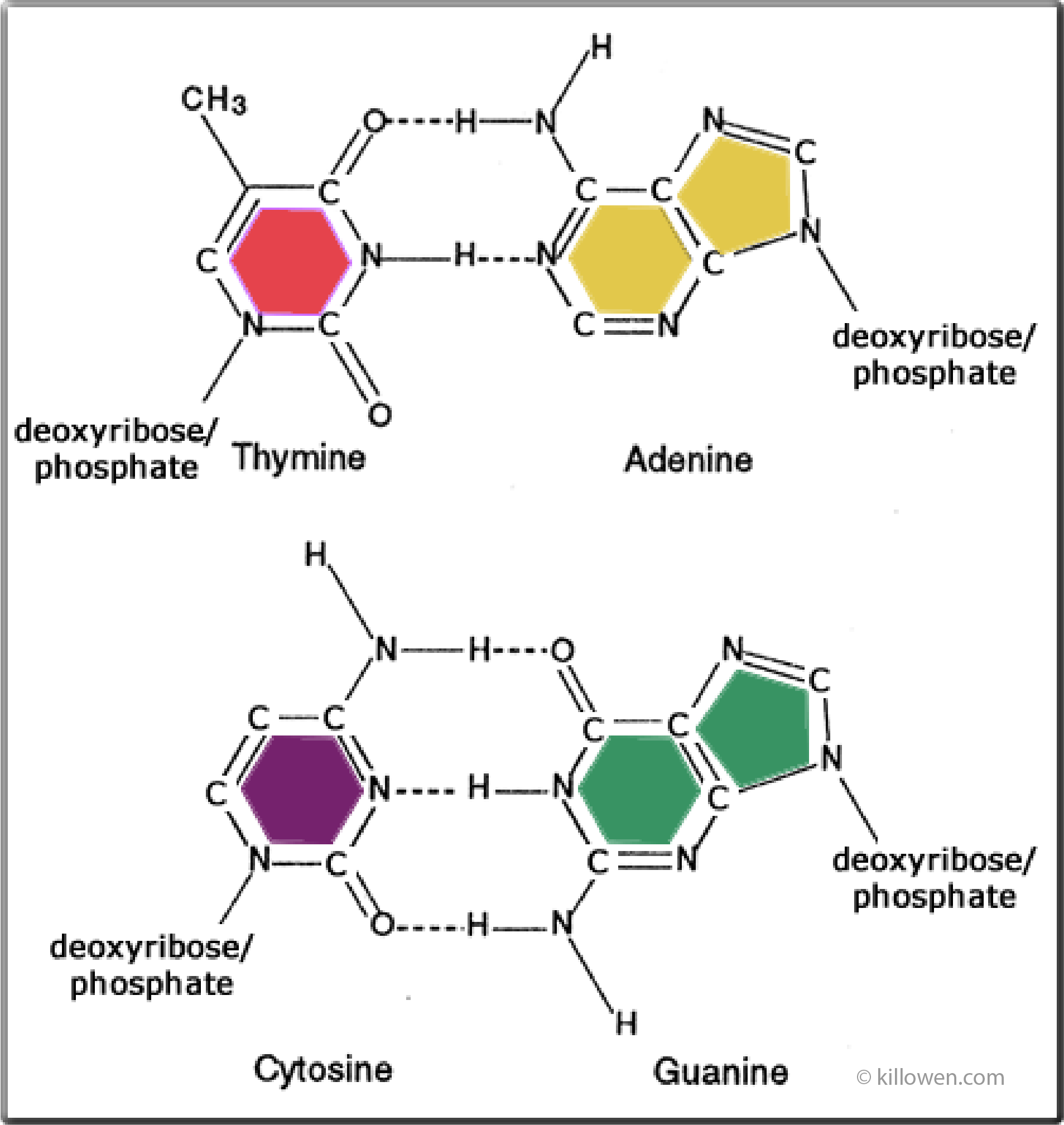
The structure of the complementary base-pairings is shown in the diagram.
Purines adenine and guanine are shown on the right-hand side with the pyrimidines thymine and cytosine on the left.
Read the original paper published by F. Crick and J. Watson in 1953:
The complementary structure of deoxyribonucleic acid
Purines adenine and guanine are shown on the right-hand side with the pyrimidines thymine and cytosine on the left.
Each base pair is held together by hydrogen bonding;
2 bonds for thymine and adenine, and 3 bonds for cytosine and guanine.
A hydrogen bond is a relatively weak chemical bond compared to a covalent bond. Here a hydrogen atom is shared between two other atoms: these atoms can be either nitrogen or oxygen.
This weak hydrogen bonding allows the DNA double helix to be unzipped by a helicase enzyme during DNA replication
Read the original paper published by F. Crick and J. Watson in 1953:
The complementary structure of deoxyribonucleic acid
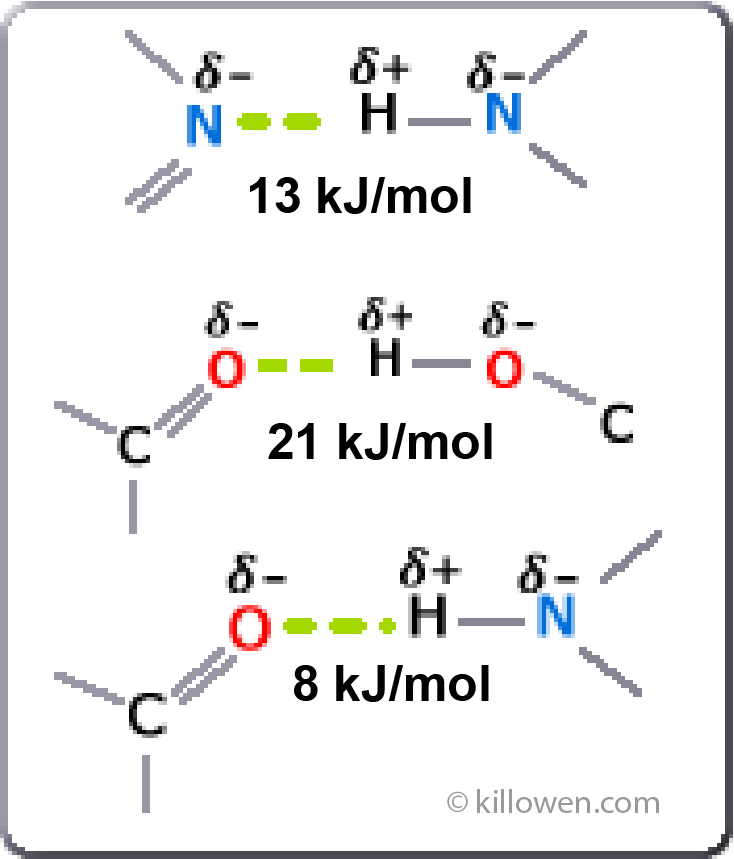
Some examples of hydrogen bonding are shown.
Note that the hydrogen atom carries a slight positive charge whilst the nitrogen or oxygen atom has a slight negative charge. The 3 atoms forming the hydrogen bond are linear and the bond itself is basically electrostatic.
The hydrogen bonding is responsible for the structure of a protein (enzyme) and hence how the protein interacts and functions. The bond being formed between any group containing an oxygen or nitrogen atom along the protein chain.
The varying strength of the hydrogen bond is shown in the diagram. The bond can be relatively easily broken compared to a covalent bond.
Note that the hydrogen atom carries a slight positive charge whilst the nitrogen or oxygen atom has a slight negative charge. The 3 atoms forming the hydrogen bond are linear and the bond itself is basically electrostatic.
The hydrogen bonding is responsible for the structure of a protein (enzyme) and hence how the protein interacts and functions. The bond being formed between any group containing an oxygen or nitrogen atom along the protein chain.
The varying strength of the hydrogen bond is shown in the diagram. The bond can be relatively easily broken compared to a covalent bond.
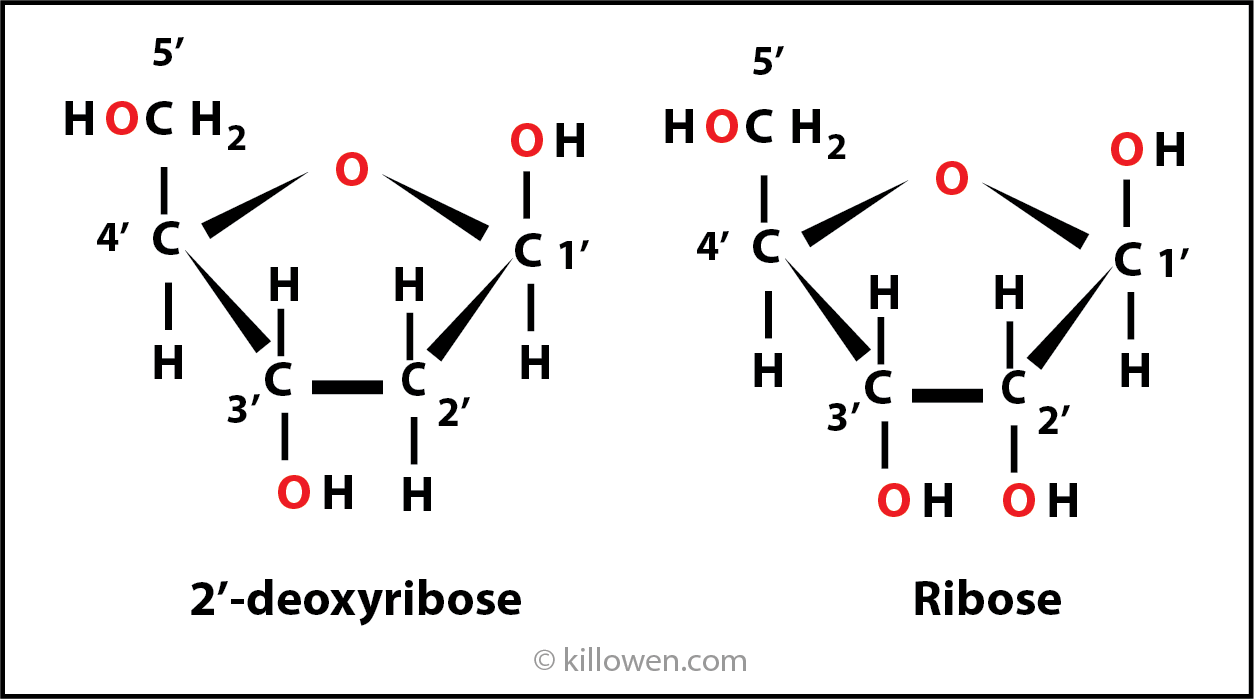
Looking at the building blocks of DNA more closely. Ribose is a pentose in which 4 carbon atoms form a ring with an oxygen. The carbon atoms are numbered 1’ to 5’.
If the oxygen atom is removed from 2’ carbon, then the molecule becomes 2’-deoxyribose.
2’-deoxyribose is found in DNA, ribose is the sugar found in RNA.
If the oxygen atom is removed from 2’ carbon, then the molecule becomes 2’-deoxyribose.
2’-deoxyribose is found in DNA, ribose is the sugar found in RNA.
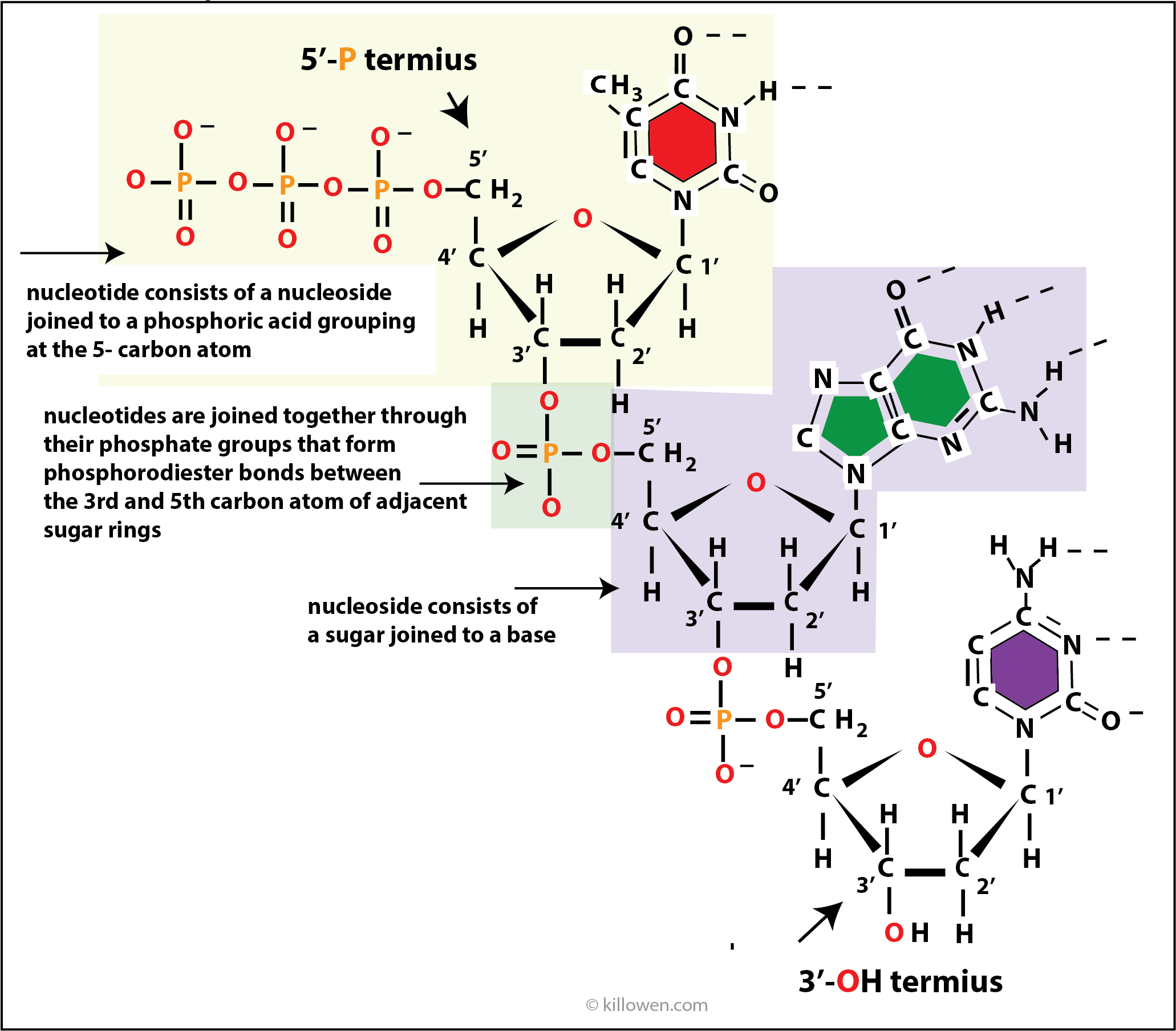
Looking at part of the strand of DNA
A nucleotide (nt) consists of a base, deoxyribose group, and a phosphodiester group.
When nucleotides are joined together they form a polynucleotide which has different ends.
At the top end in the diagram a triphosphate group completes the sequence and is attached to the 5’-carbon. This end is then called the 5’-P terminus. The other end of the sequence is completed by a -OH group . This end is called the 3’-OH terminus.
The fact that a polynucleotide has different ends ( 3’- and 5’- ) means that the DNA molecule is orientated in a very specific way. One strand runs from the 3’-end to the 5’-end. The other strand complements this and runs from the 5’-end to the 3’-end.
DNA replication as described in the next section always runs in the 5’ to 3’direction.
When nucleotides are joined together they form a polynucleotide which has different ends.
At the top end in the diagram a triphosphate group completes the sequence and is attached to the 5’-carbon. This end is then called the 5’-P terminus. The other end of the sequence is completed by a -OH group . This end is called the 3’-OH terminus.
The fact that a polynucleotide has different ends ( 3’- and 5’- ) means that the DNA molecule is orientated in a very specific way. One strand runs from the 3’-end to the 5’-end. The other strand complements this and runs from the 5’-end to the 3’-end.
DNA replication as described in the next section always runs in the 5’ to 3’direction.